Systems@TUDa
-
![]()
Systems Group Members at VLDB'25
-
![]()
Systems Group Members at Summer Retreat'25
-
![]()
Systems Group at SIGMOD'25
-
![]()
Systems Group Members at BTW'25
-
![]()
Systems Group Members at Summer Retreat'24
-
![]()
Systems Group Members at SIGMOD'24
-
![]()
Systems Group Members at Summer Retreat'23
-
![Systems Group Members 2023]()
Systems Group Members 2023
-
![Systems Group at SIGMOD'23]()
Systems Group Members at SIGMOD'23
-
![Systems Group 2022]()
Systems Group Members 2022
-
![Systems Group at VLDB22]()
Systems Group Members at VLDB'22
-
![Systems Group at SIGMOD'22]()
Systems Group Members at SIGMOD'22
-
![Systems Group at FGDB Symposium'22]()
Systems Group Members at FGDB Symposium'22
-
![]()
Systems Group at FGDB Symposium'20 in Darmstadt














- Go to picture 1
- Go to picture 2
- Go to picture 3
- Go to picture 4
- Go to picture 5
- Go to picture 6
- Go to picture 7
- Go to picture 8
- Go to picture 9
- Go to picture 10
- Go to picture 11
- Go to picture 12
- Go to picture 13
- Go to picture 14
The Systems Group at TU Darmstadt
Hello World! The Systems Group at TU Darmstadt is a collaboration of professors from the Computer Science department, pursuing research and teaching in systems topics together.
Core Topics in the Systems Group


News
-
![]()
![]()
Postdoc Anupam Sanghi joining IIT Hyderabad as Assistant Professor
September 16, 2025
-
![]()
![]()
Roman Heinrich is now a Doctor of Engineering!
September 12, 2025
Advancing Learned Cost Models For Modern Data Systems
-
![]()
![]()
Best Paper Award For JOB-Complex at AIDB@VLDB'25
September 01, 2025
JOB-Complex: A Challenging Benchmark for Traditional & Learned Query Optimization
-
![]()
![]()
Systems Group at VLDB 2025
August 30, 2025
9 Systems Group publications at VLDB'25 in London
-
![]()
![]()
Athene Young Investigator Award For Manisha Luthra
August 26, 2025
-
![]()
![]()
How Do Learned Cost Models Improve Your Database Performance?
August 07, 2025
How Good Are Learned Cost Models Really? Insights from Query Optimization Tasks
Published in SIGMOD 2025
-
![]()
![]()
Systems Group at ACM CHI 2025
April 30, 2025
Najda Geisler and Benjamin Hättasch presented two position papers at workshops of the ACM CHI Conference in Yokohama
-
![]()
![]()
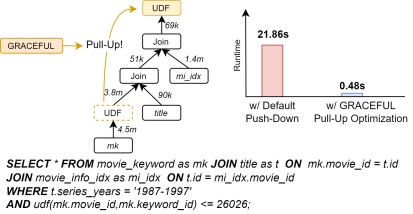
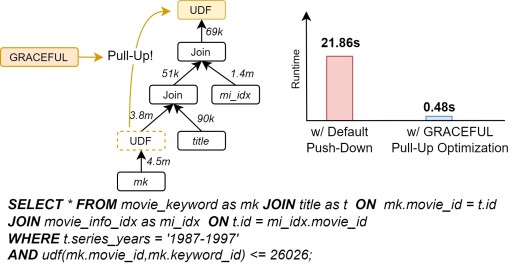
Towards Database Query Optimizers that understand UDFs
April 01, 2025
GRACEFUL: A Learned Cost Estimator For UDFs
Published in ICDE 2025
-
![]()
![]()
Towards High-performance and Trusted Cloud DBMSs – published at Datenbank Spektrum
March 10, 2025
Towards High-performance and Trusted Cloud DBMSs
-
![]()
![]()
“ELEET: Efficient Learned Query Execution over Text and Tables” Accepted to VLDB'25
February 06, 2025
ELEET: Efficient Learned Query Execution over Text and Tables














Follow us on Bluesky & LinkedIn!
We are on Bluesky and LinkedIn.
Follow us to get up-to-date information about the Systems-Group@TU-Darmstadt