Motivation
While there have been many breakthroughs in machine learning (ML) in recent years, it still requires expertise in ML to develop models for a particular domain problem. In addition, the required data is often only available in unstructured or semi-structured form and has to be integrated and cleaned before it can be used, which is a time-consuming effort. Finally, once the data has been used to train models, it is challenging for practitioners to reason about model decisions, as these are effectively black boxes. These combined disadvantages hinder the practical application of ML, especially for non-experts in the field.
Goals
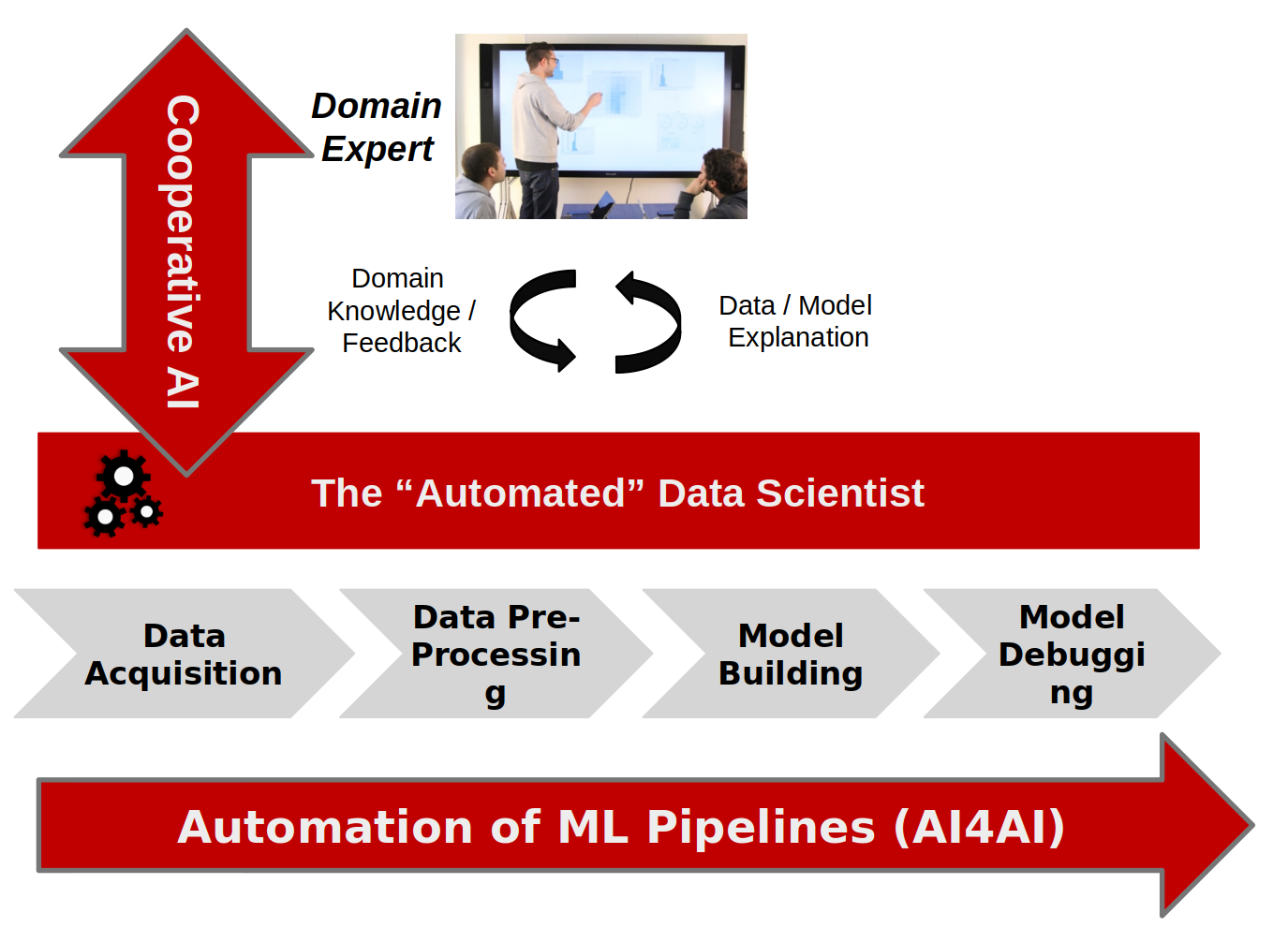
This project focuses on end-to-end automated machine learning (ML) in particular for non-expert users, which is one of the key aspects of the BMBF project “Kompetenzzentrum für Arbeit und künstliche Intelligenz im Rhein-Main-Gebiet” (KomPAKI). In particular, we will investigate the typical steps in the development of ML, i.e. data cleaning, training, validation and deployment, which require a ML background and reduce the manual effort through automation while leveraging domain knowledge and thus lowering the barrier for non-experts in ML.
First we investigate how data integration and cleansing can be automated. Today, most available data is unstructured or scattered in large data lakes. The available data usually needs to be cleaned before it can be used for ML. By automatically analyzing the available data and deriving semantic types, we can simplify this process. Furthermore, we want to explore how domain knowledge can contribute to improving the data quality.
Second, we focus on automated ML training. Today, training a ML model for a specific task requires expertise in ML, because in addition to the actual training, one has to decide which models to use and select appropriate hyperparameters. Furthermore, the data must be preprocessed to be used in models. While previous work investigates how hyperparameter tuning and model selection can be automated, we want to integrate automated preprocessing steps. While this simplifies model development, domain knowledge is still largely ignored by state-of-the-art models. Therefore, we investigate how complex models can be combined and enhanced with domain knowledge by using probabilistic logical approaches.
Finally, state-of-the-art models are black boxes, i.e. practitioners cannot reason about how the models came up with a certain prediction. Therefore, we additionally investigate how the explainability can be improved, with a special focus on the end-to-end use case, which includes data integration and pre-processing steps. In this way, a potential misbehavior of the model can be detected and the acceptance of the practitioners can be increased.
During the course of the project we will apply our techniques in practical scenarios to validate our approaches and facilitate the transfer to the pilot projects in the KomPAKI project. Finally, based on our research, we want to develop a system that will contribute to the automation of end-to-end ML.
Funding
This project is funded by the Federal Ministry of Education and Research (BMBF 02L19C150) for five years.
Researchers
| Name | Contact | |
|---|---|---|

| Nadja Geisler M.Sc. | nadja.geisler@cs.tu-... 25607 S2|02 E112 |

| Dr. rer. nat. Benjamin Hättasch Postdoctoral Researcher | benjamin.haettasch@cs.tu-... +49 6151 962702900 S2|02 E112 |

