Two Papers accepted to aiDM @ SIGMOD 2023
Matthias Urban and Manisha Luthra will present their work in Seattle.
2023/04/26
Their papers have the titles “OmniscientDB: A Large Language Model-Augmented DBMS That Knows What Other DBMSs Do Not Know” and “Zero-Shot Cost Models for Parallel Stream Processing”.
OmniscientDB: A Large Language Model-Augmented DBMS That Knows What Other DBMSs Do Not Know
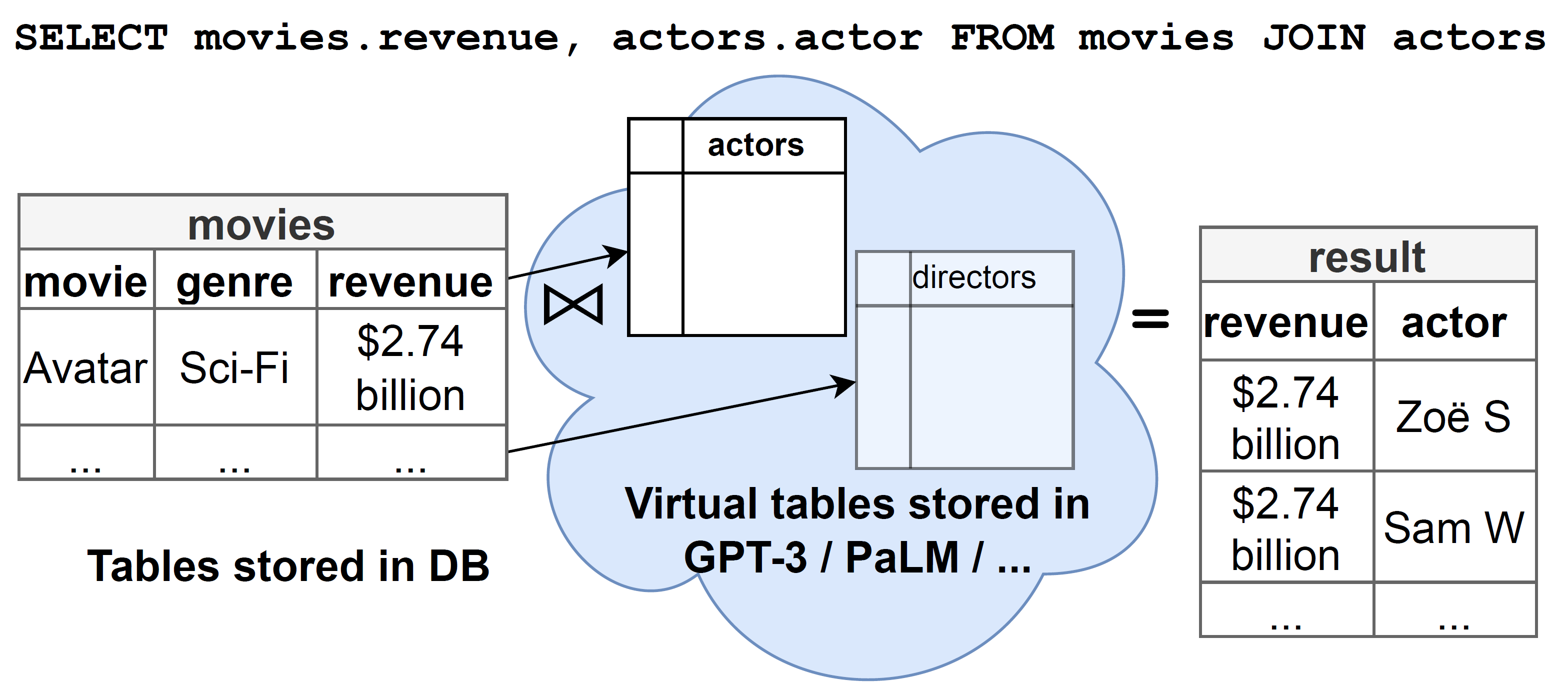
by Matthias Urban, Dac Dat and Carsten Binnig
In this paper, we present our vision of OmniscientDB, a novel database that leverages the implicitly-stored knowledge in large language models to augment datasets for analytical queries or even machine learning tasks.
OmiscientDB empowers its users to augment their datasets by means of simple SQL queries and thus has the potential to dramatically reduce the manual overhead associated with data integration.
It uses automatic prompt engineering to construct appropriate prompts for given SQL queries and passes them to a large language model like GPT-3 to contribute additional data (i.e., new rows, columns, or entire tables), augmenting the explicitly stored data.
Our initial evaluation demonstrates the general feasibility of our vision, explores different prompting techniques in greater detail, and points towards several directions for future research.
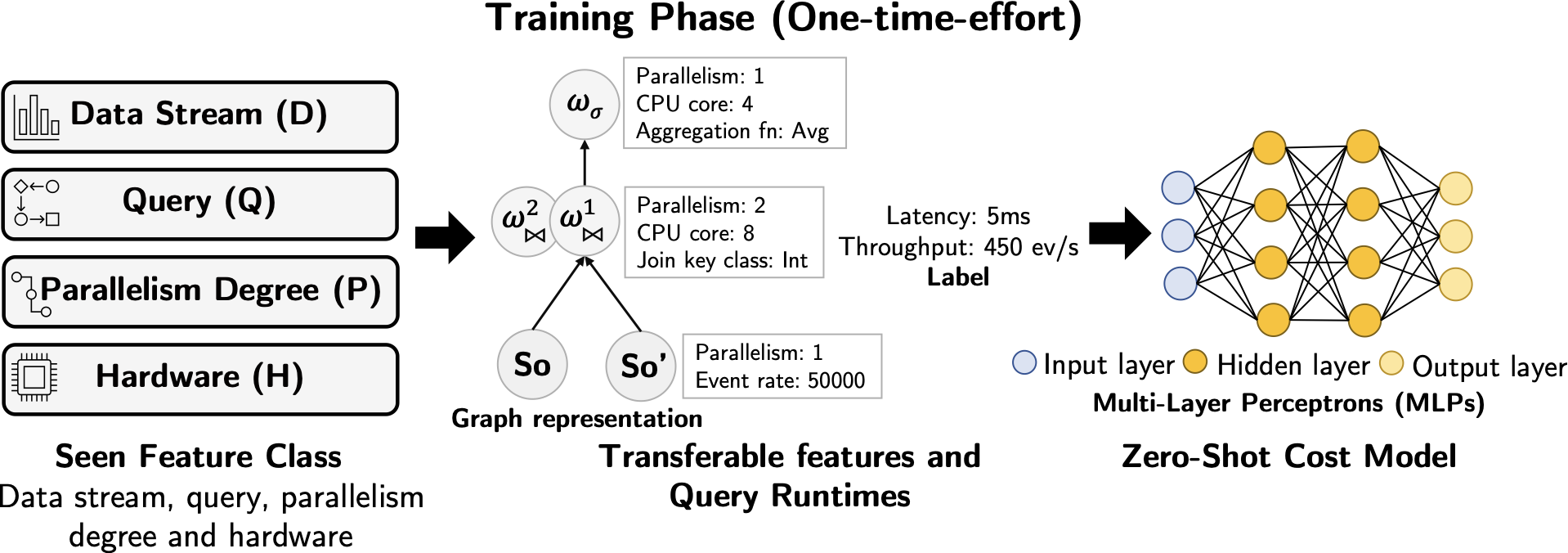
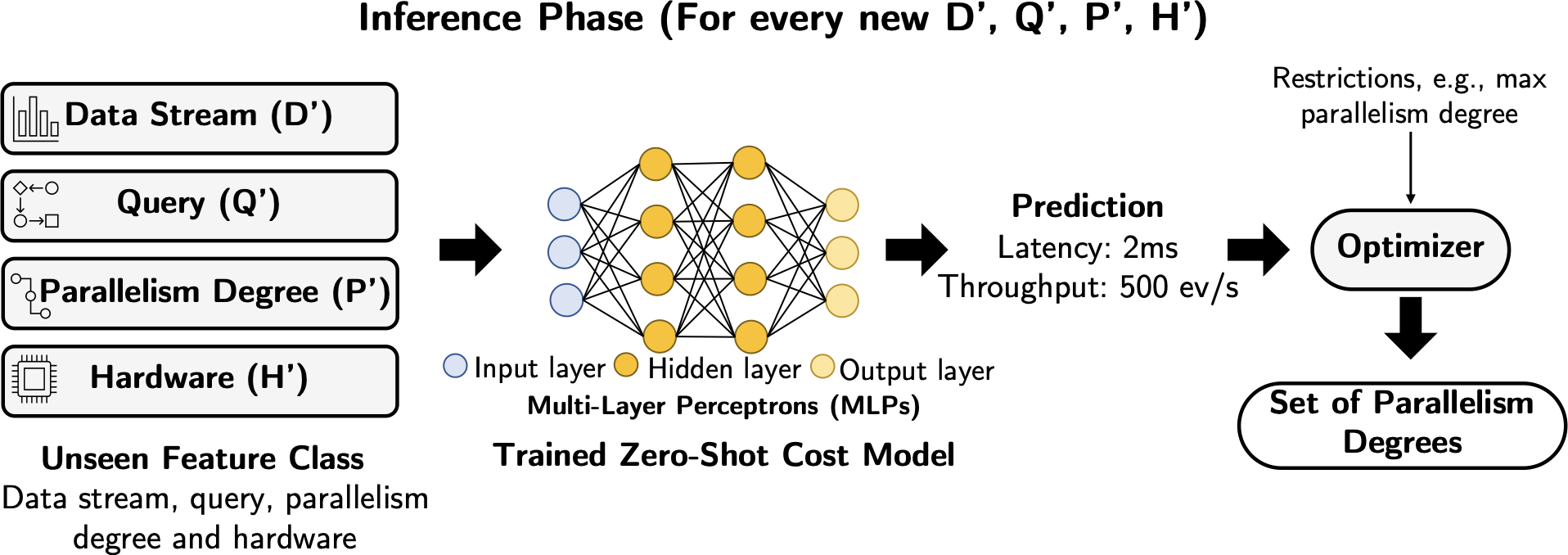
Zero-Shot Cost Models for Parallel Stream Processing
by Pratyush Agnihotri, Boris Koldehofe, Carsten Binnig and Manisha Luthra
This paper addresses the challenge of predicting the level of parallelism in distributed stream processing (DSP) systems, which are essential to deal with different high workload requirements of various industries such as e-commerce, online gaming, etc., where DSP systems are extensively used. Existing DSP systems rely on either manual tuning of parallelism degree, or workload-driven learned models for tuning parallelism, which is either not efficient or can lead to costly operator migrations and downtime when there are workload drifts. Thus, we argue for a learned model that can autonomously decide on the right parallelism degree while generalizing across workloads and meeting the current demands of DSP applications. We propose a novel approach that leverages zero-shot cost models to predict parallelism degree while generalizing across unseen streaming workloads out-of-the-box. To reduce training effort, we propose a rule-based strategy that selects parallelism degree and meaningful transferable features related to query workload and hardware that influences the parallelism decisions. We demonstrate the effectiveness of our strategy by evaluating it with numerous trained queries and show that it achieves lower costs for parallel continuous query processing.