
Motivation
The importance of thorough research under tight deadlines is increasing rapidly and the consequences for the quality of the research results are far-reaching, especially in decision-making processes. At the same time, the amount of information is growing exponentially, and there is a continuous increase of complexity, heterogeneity, and a high variation in the quality of electronic information sources.
Goal
The vision of the Research Training Group GRK 1994 AIPHES is to extract structured knowledge from heterogeneous sources using automated means in order to create dossiers of stylistically homogeneous content.

Methods
GRK 1994 AIPHES develops methods able to adapt to different genres and domains, so that the results can easily be transferred to other tasks and – in later phases of the project – to other user groups and languages. The first project phase focuses on multi-document summarization (MDS) as a prototypical task. As a representative use-case, we choose German documents on educational topics extracted from heavily heterogeneous sources.
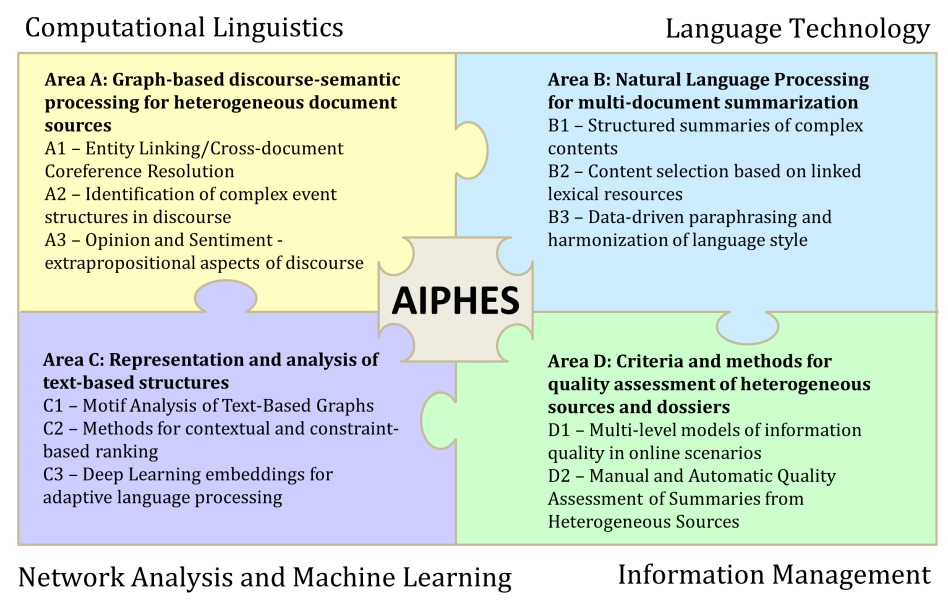
Adaptive information processing is a complex task which requires the involvement of researchers from four project areas: (A) the computational linguistic modeling of discourse phenomena in heterogeneous text genres, (B) the development of language technologies for heterogeneous MDS, (C) the representation and analysis of text-induced structures, and (D) the criteria and mechanisms for selecting and assessing the quality of heterogeneous sources and resulting summaries in information management. By investigating these questions in a densely connected research plan, the four research areas will jointly address adaptive information processing both in breadth and depth.The figure below represents the interaction of the four areas and the guiding themes of each area.
Qualification Concept
The qualification concept includes collaborations across disciplines and locations, intensive international networking, scientific consultation of at least two PhD advisors and of one international co-advisor for each doctoral project, and the responsible participation of excellent post-doctoral researchers in doctoral supervision and training jointly with experienced advisors. The graduate program will form a central location for the qualification of young researchers in the highly demanded academic field of adaptive information processing.
Guiding Themes under the responsibility of the UKP Lab
B1: Structured summaries of complex contents
B2: Content selection based on linked lexical resources
C3: Deep Learning embeddings for adaptive language processing
D1: Multi-level models of information quality in online scenarios
D2: Manual and Automatic Quality Assessment of Summaries from Heterogeneous Sources
Funding
This project was funded by Deutsche Forschungsgemeinschaft (German Research Foundation).
