
Motivation
Large scale health-related crises, such as the ongoing Covid-19 pandemic, spread fear and uncertainties across society, providing fertile soil for fake news and conspiracy theories. The current “infodemic” shows how social networks further amplify such misinformation. Changing policies, new scientific discoveries, and constantly evolving misinformation and conspiracy theories pose a severe problem to manual fact-checking.
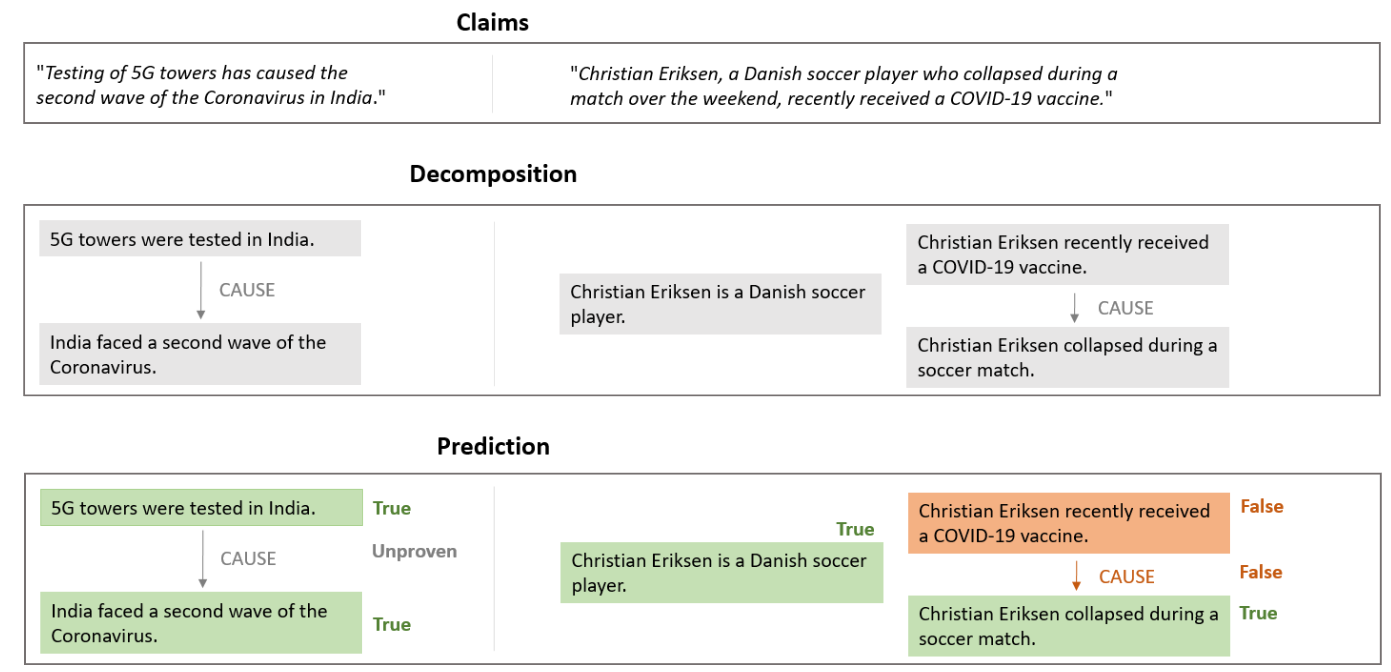
Current automatic fact-checking systems lack the ability for time-aware claim validation of such complex claims.
Goals
- Automatic decomposition of claims into easily verifiable sub-claims.
- Transparent model decisions by outputting textual rationales for a verdict.
- A fact-checking system and fine-grained annotations to automatically detect cherry-picked evidence and veracity labels for claims.
Dataset Creation
We create a high-quality dataset with real-world Covid-19 claims by using existing methods to identify check-worthy claims from social media. To identify evidence useful to verify or debunk these claims, we further utilize existing methodologies to find already fact-checked counterparts for these claims.
Method
Current fact-checkers lack the ability for time-aware claim verification, which is especially important in times of crisis, as the veracity of each claim may change quickly. Further, most approaches to automatic fact-checking verify claims by identifying whether a claim is backed up by trustworthy – and hence sparse – evidence. This makes these approaches incapable of identifying misleading claims, which omit relevant information, or of verifying complex claims.
In this project, we investigate solutions to overcome these issues by (a) creating annotations to identify misleading claims based on valid but cherry-picked evidence, and (b) simplifying fact-checking of complex claims by decomposing claims into simpler sub-claims with respect to the available evidence. To deal with the constantly changing ground truth over time, we further (c) annotate claims with respect to different pieces of evidence yielding different veracity labels for a claim. This allows for an evaluation strictly based on available evidence.
Team
- Prof. Dr. Iryna Gurevych (Principal Investigator)
- Luke Bates
- Max Glockner
Funding
This research work was funded from 2020 – 2024 by the German Federal Ministry of Research, Technology and Space and the Hessian Ministry of Higher Education, Research, Science and the Arts within their joint support of the National Research Center for Applied Cybersecurity ATHENE.

