
Motivation
The annotation of specific semantic phenomena often require compiling task-specific corpora and creating or extending task-specific knowledge bases. Presently, researchers require a broad range of skills and tools to address such semantic annotation tasks.
In the recently funded INCEpTION project, UKP Lab at TU Darmstadt aims towards building an annotation platform that incorporates all the related tasks into a joint web-based platform. The following sections briefly outline the involved tasks.
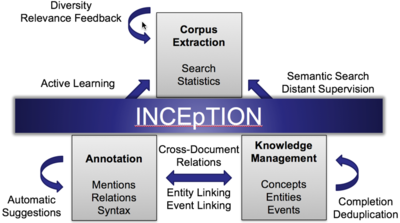
Corpus Extraction
This is the act of extracting a task-specific corpus from a larger background corpus by means of querying. This task shall be supported by automatic assistive features, e.g. interactively selecting relevant units and automatically finding similar units (i.e. getting more samples from a seed set) or reducing a large result set to a smaller but diverse result set by means of clustering similar results. The query mechanism to be used shall be able to incorporate information from the knowledge base (see knowledge management below).
Knowledge Management
This describes the ability to model knowlegde to be extracted from or connected to text. The knowledge base enables the creation of cross-document relations. We aim specifically at structured knowledge – i.e. not just flat or hierarchical tagsets, but rather entity classes and entities that may have properties and may also be linked to each other.
Text Annotation
This is the ability to perform text-level annotations. This task interacts closely with the knowledge base (see above) in terms of anchoring statements about entities and their properties in the text, i.e. to provide textual evidence for statements about entities that are already in the knowledge base or to derive statements about entities from the text.
Synergies and Assistive Support
For all of the three of the steps above, we intend to include assistive mechanisms (usually based on machine learning), e.g. to help in classification/clustering during the subcorporation step, to suggest applicable annotations in the text annotation mode, or e.g. to detect redundantly defined knowledge statements and suggest that users might link/merge them. This is an indicative list which is to be refined during the course of the project in accordance with user needs.
Funding
INCEpTION was funded by the German Research Foundation under grant № EC 503/1-1 and GU 798/21-1.
Publications

Error on loading data
An error has occured when loading publications data from TUbiblio. Please try again later.
-
{{ year }}
-
; {{ creator.name.family }}, {{ creator.name.given }}{{ publication.title }}.
; {{ editor.name.family }}, {{ editor.name.given }} (eds.); ; {{ creator }} (Corporate Creator) ({{ publication.date.toString().substring(0,4) }}):
In: {{ publication.series }}, {{ publication.volume }}, In: {{ publication.book_title }}, In: {{ publication.publication }}, {{ publication.journal_volume}} ({{ publication.number }}), ppp. {{ publication.pagerange }}, {{ publication.place_of_pub }}, {{ publication.publisher }}, {{ publication.institution }}, {{ publication.event_title }}, {{ publication.event_location }}, {{ publication.event_dates }}, ISSN {{ publication.issn }}, e-ISSN {{ publication.eissn }}, ISBN {{ publication.isbn }}, DOI: {{ publication.doi.toString().replace('http://','').replace('https://','').replace('dx.doi.org/','').replace('doi.org/','').replace('doi.org','').replace("DOI: ", "").replace("doi:", "") }}, Official URL, {{ labels[publication.type]?labels[publication.type]:publication.type }}, {{ labels[publication.pub_sequence] }}, {{ labels[publication.doc_status] }} - […]
-
Number of items in this list: >{{ publicationsList.length }}
Only the {{publicationsList.length}} latest publications are displayed here.
