
Motivation
In the age of life-long learning, the amount of educational data provided by expert services and community-based question-and-answer (QA) pages on the Web is growing fast. Although these pages provide useful information, benefiting from them is not always easy for the users. They need to go through various educational information services and query each of them individually, which entails a lot of effort on their side. They also need to figure out which of the available web pages and services is reliable and provides high-quality information. Automatically analyzing such information on the Web will help the users to access the required pieces of information with minimal effort. To this aim, we create an automatic question answering system which searches through the available educational information sources to answer the users' questions.
Goals
The basic goal of this project is to answer user questions on various educational topics. For instance “How can I do voluntary service abroad?” or “Where can I get information on studying Mathematics?” Since a large portion of users' questions have already been asked by other people and answered by experts or crowds, we use the available question and answer archives to answer these questions. The resulting system will have an interface that takes natural language questions, retrieves the requested information from various heterogeneous information sources from the web, and efficiently presents it to the user as a filtered, summarized, and quality-assessed answer. In case the system is not able to retrieve an answer, it could automatically post the question to the various community-based QA sites used in the project so that the crowd will provide an answer later on.
Another goal of the project is to investigate the impact of semantic information on community-based QA. A Semantic Role Labeling processor converts source texts into a shallow semantic representation, which provides a useful level of abstraction for other QA tasks. The system is developed for German and English, which assures that the principles and decisions used in the system can be transferred to other languages as well.
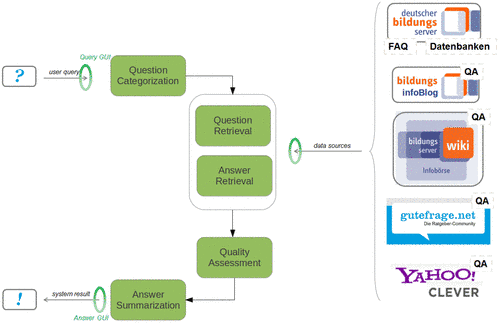
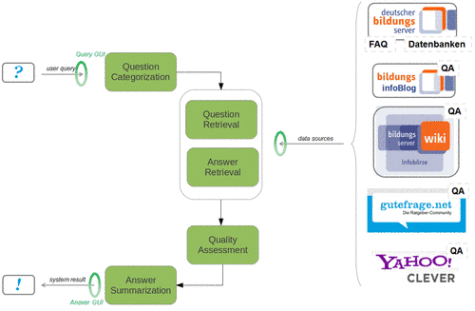
Methods
1 – Interface for natural language questions
The interface allows users to ask questions and specify the educational information sources that should be used to retrieve answers. In addition, they can define critera that should be used to assess the answer relevance.
2 – Text processing and retrieval
This part of the project collects and analyzes all pairs of question and answers that are available in FAQ collections and social QA forums. This data is then used for the online search. After a user issues a new query (i.e., a question), the system uses paraphrase recognition and information retrieval techniques to find similar questions in the collected data that have already been answered. Answers of the retrieved questions are considered as potential answers to the newly posed user question, which are further assessed with answer re-ranking methods.
3 – Quality assessment
Answer quality assessment is important in different regards, e.g., we can determine the textual quality of an answer, whether or not the answer contains offensive language, if the answer text is subjective or objective, etc. This information is then used to re-rank or filter a set of answers according to a set of chosen quality criteria.
4 – Answer summarization
If the system retrieves different relevant answers for a user question, some may contain complementary information, and others may be redundant. The system thus uses multi-document summarization techniques to summarize the most important information of the retrieved answers in regard to the user question.
5 – Semantic Role Labeling
One of the project's objectives is to evaluate the impact of semantic information on community-based question answering. Semantic Role Labeling is the task of automatically inferring shallow semantic interpretations, that describe input texts in terms of events and their participants (e.g. Who did what to whom). This information is then used to improve the quality of question categorization, answer retrieval, and summarization. There exist several theoretical frameworks for Semantic Role Labeling with different description granularity level. The choice of granularity is a trade-off between semantic richness and processing quality, and it is important to investigate which representation suits the question answering task best. Adapting existing SRL systems to the non-standard language often used in Q&A poses an additional challenge.

Funding
This project was funded by Deutsche Forschungsgemeinschaft (German Research Foundation) from 2014 – 2019. Our report on the first funding phase of the research grant is available online: QA_EduInf_Report.pdf (opens in new tab)
