Better interaction with artificial intelligence
Publication in “Nature Machine Intelligence”
2023/03/10 by Christian Meier/sip
A team of researchers from TU Darmstadt, hessian.AI and the German Research Center for Artificial Intelligence has presented a method that greatly simplifies the provision of human feedback to learning software. The work is published in the current issue of “Nature Machine Intelligence”.

The whole world is talking about ChatGPT: the AI chatbot is able to answer questions, write essays and even generate poetry. Its human writing style is a key factor in the success of this adaptive software. For Felix Friedrich of the Technical University of Darmstadt, ChatGPT is an example of how important the interaction between humans and machines is. The software's eloquence is the result not only of the millions of digital texts that it has used to train itself, but also of a refinement of this training in dialogue with humans.
Many AI algorithms are already benefiting from human feedback, as Darmstadt researchers led by Professor Kristian Kersting of the Department of Computer Science have shown in recent years. However, Felix Friedrich, who is writing his doctorate under Kersting, is convinced that the potential is far from exhausted. Together with colleagues, the computer scientist is now presenting a method that greatly simplifies the process of providing human feedback. The work is published in the current issue of the renowned journal “Nature Machine Intelligence”.
What signals contribute to an AI decision?
If we want to communicate with machines, we have to understand them. But that is rather difficult with the form of AI most frequently used at the moment, known as deep learning. Deep learning is inspired by neural connections in biological brains. Large deep learning networks have millions of connections between virtual neurons. It is difficult to understand which signals contribute to an AI decision and which don't, i.e. how the software reaches its conclusions. It resembles a black box.
“It's one of those things we don't give any thought to as long as the AI is working,” says Friedrich. However, this makes it easy to overlook when the AI takes so-called shortcuts that can lead to errors. So what are these shortcuts? Deep learning is often used to recognise certain objects in pictures, for instance polar bears. During training, it is shown lots of pictures of polar bears, to learn what common features make up a polar bear. Now, it is always possible that an AI could make things easy for itself. If there is always snow in the background of the images used for the training, then it will use this snow in the background as an identifier for a picture of a polar bear instead of the polar bear itself. So if it then sees a brown bear against a snowy landscape, the AI will incorrectly identify this as a polar bear.
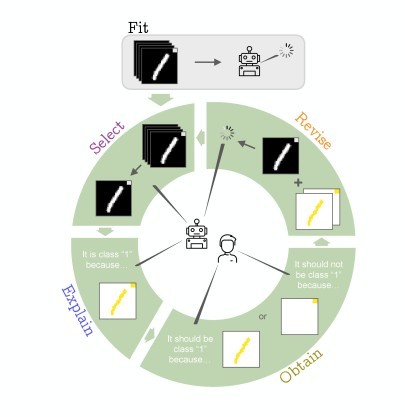
Errors like this can be detected with the help of a method called Explainable AI. The deep learning algorithm shows which patterns it used for its decision. If they were the wrong ones, a human can report this back to the AI, e.g. by showing the right patterns (such as the outline of the bear) or by marking the wrong ones as wrong. The researchers call this feedback process Explanatory Interactive Learning (XIL).
Analysis of several XIL methods
The researchers from Darmstadt have now investigated a number of existing XIL methods. “No one has ever done this systematically before,” says Felix Friedrich. The researchers meticulously analysed how the interaction with the computer occurs with the various methods and where efficiency gains are possible. They made the distinction between which of the components in an explanation are important and which are not. “It turned out that it is not necessary to report thousands of markings back to the machine, but that quite often only a handful of interactions suffice,” says Friedrich. In fact, often it is enough to tell the AI what does not belong to the object instead of defining what does.
Moreover, the researchers specifically gave an AI the task of recognising a handwritten number “1”. However, there was also a small square in the corner of each training picture. If the algorithm mistakenly took this as a relevant characteristic for the “1”, then it is enough to mark the square as not belonging to the object. “This is far more effective, because it is generally difficult to define what characterises something like a kingfisher, for instance,” explains Friedrich.
The researchers from Darmstadt have distilled a strategy (“typology”) from the investigated XIL methods that can be used to efficiently mitigate the described shortcut behaviour.
Follow-up project already started
Felix Friedrich and his colleagues are already working on the next project intended to improve the interaction between humans and machines. This time it is about text-to-image generation models, which often have a bias. When instructed to display a “firefighter”, they usually generate images of white men wearing firefighter helmets, which is due to the fact that images of white male firefighters dominate in the training data. The researchers from Darmstadt hope human interaction will help make the training data for such image generators more diverse by filtering, but also by adding more images, e.g. of firefighters with different racial appearances. This will bring Felix Friedrich closer to his goal of “human-guided machine ethics”.
The authors of the publication conduct research at the Technical University of Darmstadt, at the Hessian Center for Artificial Intelligence, and at the German Research Center for Artificial Intelligence (DFKI). The research is part of the cluster project “3AI – The Third Wave of Artificial Intelligence”.
